6. Comparison of Fixed Weights
Matt Secrest and Isaac Gravestock
Source:vignettes/weighting.Rmd
weighting.RmdIntroduction
In a psborrow2 analysis it is possible to specify fixed
weights for an observation’s log-likelihood contribution. This is
similar to a weighted regression or a fixed power prior parameter.
This vignette will show how weights can be specified and compare
regression model results with other packages. We will compare a
glm model with weights, a weighted likelihood in Stan with
psborrow2, and BayesPPD::glm.fixed.a0 for
generalized linear models with fixed a0 (power prior
parameter).
Note that we’ll need cmdstanr to run this analysis.
Please install cmdstanr if you have not done so already
following this
guide.
Logistic regression
We fit logistic regression models with the external control arm
having weights (or power parameters) equal to 0, 0.25, 0.5, 0.75, 1. The
internal treated and control patients have weight = 1. The model has a
treatment indicator and two covariates,
resp ~ trt + cov1 + cov2.
glm
logistic_glm_reslist <- lapply(c(0, 0.25, 0.5, 0.75, 1), function(w) {
logistic_glm <- glm(
resp ~ trt + cov1 + cov2,
data = as.data.frame(example_matrix),
family = binomial,
weights = ifelse(example_matrix[, "ext"] == 1, w, 1)
)
glm_summary <- summary(logistic_glm)$coef
ci <- confint(logistic_glm)
data.frame(
fitter = "glm",
borrowing = w,
variable = c("(Intercept)", "trt", "cov1", "cov2"),
estimate = glm_summary[, "Estimate"],
lower = ci[, 1],
upper = ci[, 2]
)
})BayesPPD
set.seed(123)
logistic_ppd_reslist <- lapply(c(0, 0.25, 0.5, 0.75, 1), function(w) {
logistic_ppd <- glm.fixed.a0(
data.type = "Bernoulli",
data.link = "Logistic",
y = example_matrix[example_matrix[, "ext"] == 0, ][, "resp"],
x = example_matrix[example_matrix[, "ext"] == 0, ][, c("trt", "cov1", "cov2")],
historical = list(list(
y0 = example_matrix[example_matrix[, "ext"] == 1, ][, "resp"],
x0 = example_matrix[example_matrix[, "ext"] == 1, ][, c("cov1", "cov2")],
a0 = w
)),
lower.limits = rep(-100, 5),
upper.limits = rep(100, 5),
slice.widths = rep(1, 5),
nMC = 10000,
nBI = 1000
)[[1]]
ci <- apply(logistic_ppd, 2, quantile, probs = c(0.025, 0.975))
data.frame(
fitter = "BayesPPD",
borrowing = w,
variable = c("(Intercept)", "trt", "cov1", "cov2"),
estimate = colMeans(logistic_ppd),
lower = ci[1, ],
upper = ci[2, ]
)
})psborrow2
logistic_psb_reslist <- lapply(c(0, 0.25, 0.5, 0.75, 1), function(w) {
logistic_psb2 <- create_analysis_obj(
data_matrix = as.matrix(cbind(
example_matrix,
w = ifelse(example_matrix[, "ext"] == 1, w, 1)
)),
covariates = add_covariates(c("cov1", "cov2"),
priors = prior_normal(0, 100)
),
borrowing = borrowing_full("ext"),
treatment = treatment_details("trt", prior_normal(0, 100)),
outcome = outcome_bin_logistic("resp",
baseline_prior = prior_normal(0, 1000),
weight_var = "w"
),
quiet = TRUE
)
mcmc_logistic_psb2 <- mcmc_sample(logistic_psb2, chains = 1, verbose = FALSE, seed = 123)
mcmc_summary <- mcmc_logistic_psb2$summary(
variables = c("alpha", "beta_trt", "beta[1]", "beta[2]"),
mean,
~ quantile(.x, probs = c(0.025, 0.975))
)
data.frame(
fitter = "psborrow2",
borrowing = w,
variable = c("(Intercept)", "trt", "cov1", "cov2"),
estimate = mcmc_summary$mean,
lower = mcmc_summary$`2.5%`,
upper = mcmc_summary$`97.5%`
)
})Results
logistic_res_df <- do.call(
rbind,
c(logistic_glm_reslist, logistic_ppd_reslist, logistic_psb_reslist)
)
logistic_res_df$est_ci <- sprintf(
"%.3f (%.3f, %.3f)",
logistic_res_df$estimate, logistic_res_df$lower, logistic_res_df$upper
)
wide <- reshape(
logistic_res_df[, c("fitter", "borrowing", "variable", "est_ci")],
direction = "wide",
timevar = "fitter",
idvar = c("borrowing", "variable"),
)
new_order <- order(wide$variable, wide$borrowing)
knitr::kable(wide[new_order, ], digits = 3, row.names = FALSE)| borrowing | variable | est_ci.glm | est_ci.BayesPPD | est_ci.psborrow2 |
|---|---|---|---|---|
| 0.00 | (Intercept) | 0.646 (-0.038, 1.357) | 0.691 (-0.014, 1.399) | 0.661 (-0.036, 1.359) |
| 0.25 | (Intercept) | 0.394 (-0.131, 0.931) | 0.396 (-0.131, 0.941) | 0.407 (-0.126, 0.938) |
| 0.50 | (Intercept) | 0.293 (-0.158, 0.751) | 0.297 (-0.184, 0.767) | 0.297 (-0.165, 0.760) |
| 0.75 | (Intercept) | 0.235 (-0.168, 0.642) | 0.240 (-0.175, 0.665) | 0.244 (-0.157, 0.649) |
| 1.00 | (Intercept) | 0.196 (-0.172, 0.567) | 0.202 (-0.172, 0.578) | 0.198 (-0.162, 0.560) |
| 0.00 | cov1 | -0.771 (-1.465, -0.095) | -0.809 (-1.515, -0.126) | -0.795 (-1.488, -0.107) |
| 0.25 | cov1 | -0.781 (-1.340, -0.231) | -0.793 (-1.350, -0.236) | -0.797 (-1.360, -0.239) |
| 0.50 | cov1 | -0.769 (-1.252, -0.291) | -0.776 (-1.271, -0.270) | -0.774 (-1.262, -0.289) |
| 0.75 | cov1 | -0.758 (-1.191, -0.329) | -0.769 (-1.212, -0.310) | -0.771 (-1.215, -0.350) |
| 1.00 | cov1 | -0.749 (-1.145, -0.357) | -0.761 (-1.152, -0.369) | -0.755 (-1.148, -0.368) |
| 0.00 | cov2 | -0.730 (-1.472, -0.008) | -0.745 (-1.496, -0.004) | -0.756 (-1.512, -0.029) |
| 0.25 | cov2 | -0.559 (-1.114, -0.014) | -0.568 (-1.124, -0.023) | -0.572 (-1.130, -0.012) |
| 0.50 | cov2 | -0.459 (-0.926, 0.003) | -0.471 (-0.953, -0.003) | -0.467 (-0.920, -0.012) |
| 0.75 | cov2 | -0.398 (-0.811, 0.011) | -0.402 (-0.814, 0.006) | -0.404 (-0.826, -0.000) |
| 1.00 | cov2 | -0.358 (-0.731, 0.013) | -0.358 (-0.736, 0.022) | -0.359 (-0.726, 0.006) |
| 0.00 | trt | 0.154 (-0.558, 0.871) | 0.137 (-0.572, 0.864) | 0.164 (-0.555, 0.898) |
| 0.25 | trt | 0.349 (-0.183, 0.885) | 0.361 (-0.170, 0.899) | 0.358 (-0.172, 0.890) |
| 0.50 | trt | 0.405 (-0.082, 0.894) | 0.415 (-0.068, 0.916) | 0.407 (-0.089, 0.907) |
| 0.75 | trt | 0.434 (-0.031, 0.900) | 0.436 (-0.031, 0.913) | 0.434 (-0.031, 0.898) |
| 1.00 | trt | 0.452 (-0.000, 0.905) | 0.456 (-0.010, 0.909) | 0.454 (0.006, 0.918) |
logistic_res_df$borrowing_x <- logistic_res_df$borrowing +
(as.numeric(factor(logistic_res_df$fitter)) - 3) / 100
ggplot(logistic_res_df, aes(x = borrowing_x, y = estimate, group = fitter, colour = fitter)) +
geom_errorbar(aes(ymin = lower, ymax = upper)) +
geom_point() +
facet_wrap(~variable, scales = "free")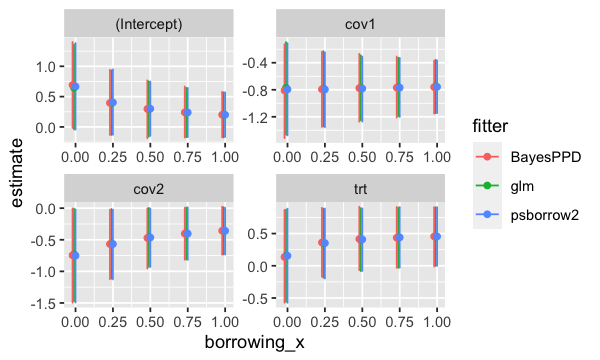
plot of chunk logistic_plot
Exponential models
Now we fit models with an exponentially distributed outcome. There is
no censoring in this data set. For glm we use
family = Gamma(link = "log") and specify fixed
dispersion = 1 to fit a exponential model. As before, the
external control arm having weights (or power parameters) equal to 0,
0.25, 0.5, 0.75, 1. The internal treated and control patients have
weight = 1. The model has a treatment indicator and two covariates,
eventtime ~ trt + cov1 + cov2.
set.seed(123)
sim_data_exp <- cbind(
simsurv::simsurv(
dist = "exponential",
x = as.data.frame(example_matrix[, c("trt", "cov1", "cov2", "ext")]),
betas = c("trt" = 1.3, "cov1" = 1, "cov2" = 0.1, "ext" = -0.4),
lambdas = 5
),
example_matrix[, c("trt", "cov1", "cov2", "ext")],
censor = 0
)
head(sim_data_exp)
# id eventtime status trt cov1 cov2 ext censor
# 1 1 0.14802638 1 0 0 1 0 0
# 2 2 0.05065174 1 0 1 0 0 0
# 3 3 0.01727805 1 0 1 0 0 0
# 4 4 0.13168620 1 0 1 0 0 0
# 5 5 0.07740706 1 0 0 0 0 0
# 6 6 0.04999778 1 0 1 0 0 0
## glm
glm_reslist <- lapply(c(0, 0.25, 0.5, 0.75, 1), function(w) {
exp_glm <- glm(
eventtime ~ trt + cov1 + cov2,
data = sim_data_exp,
family = Gamma(link = "log"),
weights = ifelse(sim_data_exp$ext == 1, w, 1)
)
glm_summary <- summary(exp_glm, dispersion = 1)
est <- -glm_summary$coefficients[, "Estimate"]
lower <- est - 1.96 * glm_summary$coefficients[, "Std. Error"]
upper <- est + 1.96 * glm_summary$coefficients[, "Std. Error"]
data.frame(
fitter = "glm",
borrowing = w,
variable = c("(Intercept)", "trt", "cov1", "cov2"),
estimate = est,
lower = lower,
upper = upper
)
})
## BayesPPD
set.seed(123)
ppd_reslist <- lapply(c(0, 0.25, 0.5, 0.75, 1), function(w) {
exp_ppd <- glm.fixed.a0(
data.type = "Exponential",
data.link = "Log",
y = sim_data_exp[sim_data_exp$ext == 0, ]$eventtime,
x = as.matrix(sim_data_exp[sim_data_exp$ext == 0, c("trt", "cov1", "cov2")]),
historical = list(list(
y0 = sim_data_exp[sim_data_exp$ext == 1, ]$eventtime,
x0 = as.matrix(sim_data_exp[sim_data_exp$ext == 1, c("cov1", "cov2")]),
a0 = w
)),
lower.limits = rep(-100, 5),
upper.limits = rep(100, 5),
slice.widths = rep(1, 5),
nMC = 10000,
nBI = 1000
)[[1]]
ci <- apply(exp_ppd, 2, quantile, probs = c(0.025, 0.975))
data.frame(
fitter = "BayesPPD",
borrowing = w,
variable = c("(Intercept)", "trt", "cov1", "cov2"),
estimate = colMeans(exp_ppd),
lower = ci[1, ],
upper = ci[2, ]
)
})
## psborrow2
psb_reslist <- lapply(c(0, 0.25, 0.5, 0.75, 1), function(w) {
exp_psb2 <- create_analysis_obj(
data_matrix = as.matrix(cbind(sim_data_exp, w = ifelse(example_matrix[, "ext"] == 1, w, 1))),
covariates = add_covariates(c("cov1", "cov2"),
priors = prior_normal(0, 100)
),
borrowing = borrowing_full("ext"),
treatment = treatment_details("trt", prior_normal(0, 100)),
outcome = outcome_surv_exponential("eventtime", "censor",
baseline_prior = prior_normal(0, 1000),
weight_var = "w"
),
quiet = TRUE
)
mcmc_exp_psb2 <- mcmc_sample(exp_psb2, chains = 1, verbose = FALSE, seed = 123)
mcmc_summary <- mcmc_exp_psb2$summary(
variables = c("alpha", "beta_trt", "beta[1]", "beta[2]"),
mean,
~ quantile(.x, probs = c(0.025, 0.975))
)
data.frame(
fitter = "psborrow2",
borrowing = w,
variable = c("(Intercept)", "trt", "cov1", "cov2"),
estimate = mcmc_summary$mean,
lower = mcmc_summary$`2.5%`,
upper = mcmc_summary$`97.5%`
)
})
knitr::knit_hooks$set(output = output_hook)Results
Note: Wald confidence intervals are displayed here for
glm for the exponential models.
res_df <- do.call(rbind, c(glm_reslist, ppd_reslist, psb_reslist))
res_df$est_ci <- sprintf(
"%.3f (%.3f, %.3f)",
res_df$estimate, res_df$lower, res_df$upper
)
wide <- reshape(
res_df[, c("fitter", "borrowing", "variable", "est_ci")],
direction = "wide",
timevar = "fitter",
idvar = c("borrowing", "variable"),
)
new_order <- order(wide$variable, wide$borrowing)
knitr::kable(wide[new_order, ], digits = 3, row.names = FALSE)| borrowing | variable | est_ci.glm | est_ci.BayesPPD | est_ci.psborrow2 |
|---|---|---|---|---|
| 0.00 | (Intercept) | 1.930 (1.597, 2.263) | 1.915 (1.572, 2.236) | 1.916 (1.563, 2.245) |
| 0.25 | (Intercept) | 1.581 (1.323, 1.838) | 1.567 (1.308, 1.814) | 1.568 (1.311, 1.811) |
| 0.50 | (Intercept) | 1.473 (1.251, 1.695) | 1.466 (1.247, 1.685) | 1.466 (1.237, 1.684) |
| 0.75 | (Intercept) | 1.414 (1.215, 1.613) | 1.407 (1.208, 1.601) | 1.412 (1.211, 1.604) |
| 1.00 | (Intercept) | 1.376 (1.194, 1.558) | 1.369 (1.183, 1.551) | 1.370 (1.188, 1.547) |
| 0.00 | cov1 | 0.630 (0.300, 0.959) | 0.630 (0.304, 0.960) | 0.631 (0.298, 0.966) |
| 0.25 | cov1 | 0.722 (0.453, 0.991) | 0.729 (0.459, 1.013) | 0.728 (0.461, 1.003) |
| 0.50 | cov1 | 0.786 (0.552, 1.020) | 0.789 (0.559, 1.026) | 0.790 (0.556, 1.029) |
| 0.75 | cov1 | 0.827 (0.616, 1.037) | 0.829 (0.622, 1.044) | 0.825 (0.618, 1.037) |
| 1.00 | cov1 | 0.854 (0.662, 1.046) | 0.859 (0.668, 1.057) | 0.856 (0.667, 1.052) |
| 0.00 | cov2 | 0.043 (-0.309, 0.395) | 0.039 (-0.318, 0.382) | 0.036 (-0.322, 0.378) |
| 0.25 | cov2 | -0.009 (-0.273, 0.255) | -0.008 (-0.283, 0.252) | -0.011 (-0.272, 0.249) |
| 0.50 | cov2 | 0.009 (-0.213, 0.232) | 0.007 (-0.218, 0.226) | 0.006 (-0.213, 0.223) |
| 0.75 | cov2 | 0.023 (-0.173, 0.220) | 0.024 (-0.172, 0.216) | 0.022 (-0.175, 0.216) |
| 1.00 | cov2 | 0.033 (-0.144, 0.211) | 0.033 (-0.145, 0.206) | 0.034 (-0.140, 0.212) |
| 0.00 | trt | 1.256 (0.911, 1.601) | 1.260 (0.911, 1.629) | 1.260 (0.909, 1.613) |
| 0.25 | trt | 1.564 (1.306, 1.822) | 1.563 (1.302, 1.816) | 1.564 (1.303, 1.823) |
| 0.50 | trt | 1.622 (1.386, 1.859) | 1.620 (1.383, 1.851) | 1.618 (1.382, 1.851) |
| 0.75 | trt | 1.649 (1.422, 1.875) | 1.646 (1.414, 1.871) | 1.644 (1.413, 1.867) |
| 1.00 | trt | 1.664 (1.443, 1.884) | 1.660 (1.438, 1.874) | 1.660 (1.438, 1.878) |
res_df$borrowing_x <- res_df$borrowing +
(as.numeric(factor(res_df$fitter)) - 3) / 100
ggplot(res_df, aes(x = borrowing_x, y = estimate, group = fitter, colour = fitter)) +
geom_errorbar(aes(ymin = lower, ymax = upper)) +
geom_point() +
facet_wrap(~variable, scales = "free")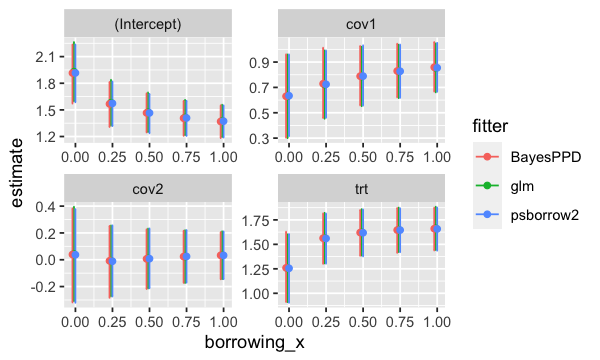
plot of chunk exp_plot