2. Matching and Weighting Application with Dynamic Borrowing
Manoj Khanal khanal_manoj@lilly.com
Eli Lilly & Company
2026-05-12
Source:vignettes/match_weight_02_application.Rmd
match_weight_02_application.RmdIn the previous
article on matching/weighting methods, we had used various
matching/weighting methods to minimize selection bias. In this article,
we will use matched/weighted cohort for Bayesian dynamic borrowing. This
article is a follow-up to the matching/weighting article, which
demonstrates methods to mitigate selection bias when designing
externally controlled trial. In this article, we will illustrate
Bayesian dynamic borrowing approaches using the matched and weighted
cohort. We will use the psborrow2(Isaac Gravestock 2024) R package to demonstrate
the use of Bayesian methods with an example for time to event outcome.
In addition to using psborrow2 package, we will also
demonstrate how to implement power and commensurate prior models with
piecewise exponential baseline hazard function.
We consider the following time to event outcome models in this article
- Exponential distribution with constant hazard
- Weibull distribution with proportional hazards parametrization
- Piecewise Exponential distribution (not implemented yet in
psborrow2R package)
We will also consider several Bayesian dynamic borrowing methods
- Commensurate prior
- Power prior
Hazard function
The hazard function of at time is defined as the instantaneous rate of the event occurrence that is still at risk at time . It is defined as
$$\begin{equation} h(t)=\lim_\limits{\Delta \rightarrow 0 } P\frac{(t\leq T<t+\Delta t|T\geq t)}{\Delta t}=\frac{f(t)}{S(t)}, \end{equation}$$
where is the density function of given , and is the survival function of .
Cox proportional hazards model
We start with the Cox proportional hazards model (Cox 1972) for observation as follows. To estimate the regression coefficients under the Bayesian framework, the baseline hazard function needs to be specified. This is not the case under a Frequentist Cox regression. The hazard at time is
where is the vector of baseline covariates and is the treatment indicator.
Baseline hazard function
Baseline hazard functions can be modeled using common probability distributions in survival analysis, such as exponential, Weibull, and Gompertz. However, these standard specifications have limited flexibility and cannot capture irregular behaviors. Alternatively, more flexible hazard shapes can be specified using piecewise constant, piecewise exponential or spline functions, allowing for the representation of multimodal patterns and accommodating diverse irregularities (Lázaro et al. 2021). The misspecification of the baseline hazard can lead to the loss of important model details which can be challenging to accurately estimate outcomes of interest, such as probabilities or survival curves. In this article, we consider the following baseline hazard functions.
- Exponential distribution with constant hazard
- Weibull distribution with proportional hazards parametrization
- with shape parameter and scale parameter .
- Piecewise exponential distribution
- for where is the interval and is the total number of pre-specified intervals as in Murray et al. (2014). In our example below, we will consider to the percentile of the event times from the treated group.
Likelihood
We now introduce the likelihood along with the weight which is a subject specific weight. For the purpose of demonstration, we have considered the subject specific weight from inverse probability of treatment weighting method estimating ATT. In other words, for subject in RCT and for subject in RWD. Let be the observed time, be an event indicator, be the covariates, and be the treatment indicator in the trial data. Similarly, let be the observed time, be an event indicator, be the covariates and be the treatment indicator in external control data. The time axis is partitioned into intervals: . Let be the piecewise exponential baseline hazard function with for . Denote . Let and be the covariate and treatment effects respectively in trial. Similarly, let and represent the parameters in external control.
The joint likelihood of trial and external control for right censored observations after taking account the weight with baseline hazard as a piecewise exponential function and intervals can be written by slightly extending Murray et al. (2014) as
$$ \begin{equation} \small \begin{split} & L(\boldsymbol{\alpha},\boldsymbol{\beta},\boldsymbol{\gamma},\boldsymbol{\alpha}_0,\boldsymbol{\beta}_0 |\boldsymbol{D},\boldsymbol{D}_0 ) \\ & = L(\boldsymbol{\alpha},\boldsymbol{\beta},\boldsymbol{\gamma}|\boldsymbol{D},\boldsymbol \mu) L(\boldsymbol{\alpha}_0,\boldsymbol{\beta}_0|\boldsymbol{D}_0) \\ & =\prod_{i=1}^n \prod_{k=1}^K \Bigg[\exp{\bigg\{\mathcal I(Y_{i} \in I_k)\mathcal S_{ik}\bigg\}}^{\delta_{i}} \exp\bigg\{-\mathcal I(Y_{i} \in I_k) \bigg( \sum_{\ell=1}^{k-1} (\kappa_\ell - \kappa_{\ell-1}) \\ & \times \exp{(\mathcal S_{i\ell})} + (Y_{i} - \kappa_{k-1}) \exp{(\mathcal S_{ik}) } \bigg) \bigg\} \Bigg] \Bigg[ \exp{\bigg\{\mathcal I(Y_{0,i} \in I_k) \mathcal S_{0,ik} \bigg\} }^{\delta_{0,i}} \\ & \times \exp\bigg\{-\mathcal I(Y_{0,i} \in I_k) \bigg( \sum_{\ell=1}^{k-1} (\kappa_\ell - \kappa_{\ell-1})\exp{(\mathcal S_{0,i\ell})} + (Y_{0,i} - \kappa_{k-1})\\ & \times \exp{(\mathcal S_{0,ik}) } \bigg) \bigg\} \Bigg], \end{split} \end{equation} $$
where , , ; and are the sample size in trial and external control data respectively. If , then the above likelihood becomes the traditional likelihood for Cox proportional hazards model. Above notations are similar as in Khanal (2022).
The joint likelihood can also be constructed in a similar way for other baseline hazard functions.
Power prior model
We denote the data for the randomized controlled trial (RCT) as with the corresponding likelihood as and external control (EC) data as with corresponding likelihood as . The formulation of power prior is (Ibrahim et al. 2015) where is the vector of subject specific weights in the EC data, and , , and are the priors for , and respectively.
The posterior distribution is
We consider the non-informative prior distributions for the parameters as , for with baseline covariates, and for intervals.
Note: To avoid confusion, means a normal distribution with mean and precision .
Commensurate prior model
Let and be the parameter vector for RCT and RWD respectively. We consider the following commensurate prior
where is the precision parameter that determines the degree of borrowing, is the total number of covariates and is the total number of intervals. For the precision parameter, we assign a gamma prior as .
Conducting Analysis
We first load the following libraries.
#Loading the libraries
library(R2jags)
library(psborrow2)
library(cmdstanr)
library(posterior)
library(bayesplot)
library(kableExtra)
library(survival)Example data
We also load the data set data_with_weights.
- The continuous variables are
-
Age(years) -
Weight(lbs) -
Height(inches) Biomarker1Biomarker2
-
- The categorical variables are
-
Smoker: Yes = 1 and No = 0 -
Sex: Male = 1 and Female = 0 -
ECOG1: ECOG 1 = 1 and ECOG 0 = 0
-
- The treatment indicator is
-
group: group = 1 is treatment and group = 0 is placebo
-
- The time to event variable is
time
- The event indicator variable is
-
event: event = 1 represents an event occurred and event = 0 indicates the event was censored
-
- The data source indicator variable is
-
indicator: indicator=1 is the RCT data and indicator=0 is the EC data
-
- The estimated weights after applying matching/weighting methods are
-
ratio1_caliper_weights_lps: Weights after 1:1 Nearest Neighbor Propensity score matching with a caliper width of 0.2 of the standard deviation of the logit of the propensity score -
ratio_caliper_weights: Weights after 1:1 Nearest Neighbor Propensity score matching with a caliper width of 0.2 of the standard deviation of raw propensity score -
genetic_ratio1_weights: Weights after 1:1 Genetic matching with replacement -
genetic_ratio1_weights_no_replace: Weights after 1:1 Genetic matching without replacement -
optimal_ratio1_weights: Weights after 1:1 Optimal matching -
weights_gbm: Weights (ATT) after using Generalized Boosted Model to estimate propensity score -
eb_weights: Weights (ATT) after Entropy Balancing -
invprob_weights: Weights (ATT) after Inverse Probability Treatment Weighting using logistic regression
-
data_with_weights <- read.csv("data_with_weights.csv")
data_with_weights$cnsr <- 1 - data_with_weights$event
data_with_weights <- data_with_weights[, sapply(data_with_weights, class) %in% c("numeric", "integer")]
data_with_weights$ext <- 1 - data_with_weights$indicator #External control flag
data_with_weights$norm.weights=data_with_weights$invprob_weights
data_with_weights$norm.weights[data_with_weights$ext==1]=data_with_weights$norm.weights[data_with_weights$ext==1]/max(data_with_weights$norm.weights[data_with_weights$ext==1])
data_with_weights <- as.matrix(data_with_weights)The first six observations of the data set is shown below.
head(data_with_weights)
#> X Age Weight Height Biomarker1 Biomarker2 Smoker Sex ECOG1 group
#> [1,] 1 56.63723 150.8678 65.79587 39.69306 47.71659 0 1 0 1
#> [2,] 2 52.21456 145.0049 63.72807 29.83998 48.36954 1 1 1 1
#> [3,] 3 53.46470 146.6449 63.73311 37.64033 48.64362 0 0 0 0
#> [4,] 4 51.89528 147.6856 66.44799 41.08949 46.04826 1 1 1 1
#> [5,] 5 52.17130 151.8084 66.16895 34.48727 51.26657 1 1 1 0
#> [6,] 6 57.01979 144.6115 64.03365 34.82447 52.03498 0 1 0 0
#> time event indicator ratio1_caliper_weights_lps
#> [1,] 0.4089043 0 1 1
#> [2,] 0.9721405 0 1 0
#> [3,] 0.2956919 0 1 1
#> [4,] 4.3111823 0 1 1
#> [5,] 0.2644848 0 1 0
#> [6,] 0.3103544 0 1 1
#> ratio1_caliper_weights genetic_ratio1_weights
#> [1,] 1 1
#> [2,] 0 1
#> [3,] 1 1
#> [4,] 1 1
#> [5,] 0 1
#> [6,] 0 1
#> genetic_ratio1_weights_no_replace optimal_ratio1_weights weights_gbm
#> [1,] 0 1 1
#> [2,] 1 1 1
#> [3,] 0 1 1
#> [4,] 0 1 1
#> [5,] 1 1 1
#> [6,] 1 1 1
#> eb_weights invprob_weights cnsr ext norm.weights
#> [1,] 1 1 1 0 1
#> [2,] 1 1 1 0 1
#> [3,] 1 1 1 0 1
#> [4,] 1 1 1 0 1
#> [5,] 1 1 1 0 1
#> [6,] 1 1 1 0 1Exponential distribution with constant hazard with gamma prior
distribution (Using psborrow2 R package)
The psborrow2 package will be used to conduct the
analysis.
We use exponential distribution for the outcome model as follows.
Non-informative normal prior is used for the baseline parameter. The
data data_with_weights contain the time and censoring
variable. For demonstration purpose, we choose the subject level weight
invprob_weights calculated using inverse probability of
treatment weighting (IPTW). In this step we extract the time, censoring
indicator and the normalized weight variables denoted by
time, cnsr and norm.weights
respectively.
#Outcome
outcome <- outcome_surv_exponential(
time_var = "time",
cens_var = "cnsr",
baseline_prior = prior_normal(0, 1000),
weight_var = "norm.weights"
)
outcome
#> Outcome object with class OutcomeSurvExponential
#>
#> Outcome variables:
#> time_var cens_var weight_var
#> "time" "cnsr" "norm.weights"
#>
#> Baseline prior:
#> Normal Distribution
#> Parameters:
#> Stan R Value
#> mu mean 0
#> sigma sd 1000Next, the borrowing method is implemented as shown below. We consider
Bayesian Dynamic Borrowing (BDB) in which gamma prior is assigned for
the commensurability parameter. The tau_prior shown below
is the hyperparameter of the commensurate prior which determines the
degree of borrowing. We assign a gamma prior for this hyperparameter.
Furthermore, we also need to specify a flag for external data which is
denoted by ext.
#Borrowing
borrowing <- borrowing_hierarchical_commensurate(
ext_flag_col = "ext",
tau_prior = prior_gamma(0.001, 0.001)
)
borrowing
#> Borrowing object using the Bayesian dynamic borrowing with the hierarchical commensurate prior approach
#>
#> External control flag: ext
#>
#> Commensurability parameter prior:
#> Gamma Distribution
#> Parameters:
#> Stan R Value
#> alpha shape 0.001
#> beta rate 0.001
#> Constraints: <lower=0>Similarly, details regarding the treatment variable is specified below. A Non-informative prior is used for the treatment effect parameter .
#Treatment
treatment <- treatment_details(
trt_flag_col = "group",
trt_prior = prior_normal(0, 1000)
)
treatment
#> Treatment object
#>
#> Treatment flag column: group
#>
#> Treatment effect prior:
#> Normal Distribution
#> Parameters:
#> Stan R Value
#> mu mean 0
#> sigma sd 1000Now, all the pieces are brought together to create the analysis object as shown below.
#Application
anls_obj <- create_analysis_obj(
data_matrix = data_with_weights,
outcome = outcome,
borrowing = borrowing,
treatment = treatment
)
#> Inputs look good.
#> Stan program compiled successfully!
#> Ready to go! Now call `mcmc_sample()`.Finally, we run the MCMC sample for iterations with chains.
niter = 10000
results.exp.psborrow<- mcmc_sample(anls_obj,
iter_warmup = round(niter/3),
iter_sampling = niter,
chains = 3,
seed = 123
)
#> Running MCMC with 3 sequential chains...
#>
#> Chain 1 finished in 7.2 seconds.
#> Chain 2 finished in 7.1 seconds.
#> Chain 3 finished in 9.4 seconds.
#>
#> All 3 chains finished successfully.
#> Mean chain execution time: 7.9 seconds.
#> Total execution time: 23.9 seconds.
draws1 <- results.exp.psborrow$draws()
draws1 <- rename_draws_covariates(draws1, anls_obj)The summary is shown below.
results.exp.psborrow$summary()
#> # A tibble: 6 × 10
#> variable mean median sd mad q5 q95 rhat ess_bulk
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 lp__ -718. -718. 1.48 1.28 -721. -716. 1.00 10917.
#> 2 beta_trt -0.358 -0.358 0.109 0.108 -0.537 -0.179 1.00 13767.
#> 3 alpha[1] -0.621 -0.620 0.0904 0.0902 -0.771 -0.475 1.00 13896.
#> 4 alpha[2] 2.36 2.38 0.368 0.363 1.72 2.92 1.00 16892.
#> 5 tau 0.119 0.0507 0.181 0.0697 0.000480 0.463 1.00 12986.
#> 6 HR_trt 0.704 0.699 0.0768 0.0756 0.585 0.836 1.00 13767.
#> # ℹ 1 more variable: ess_tail <dbl>The histogram of the posterior samples for hazard ratio and commensurability parameter as shown below.
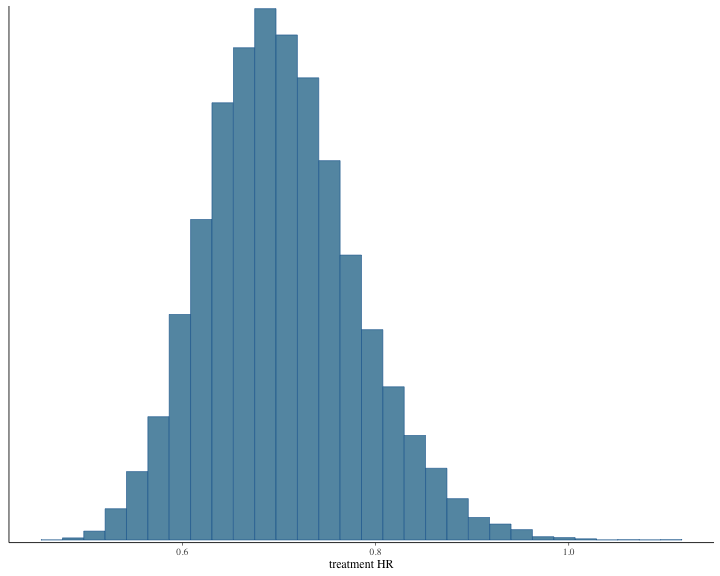
plot of chunk unnamed-chunk-10
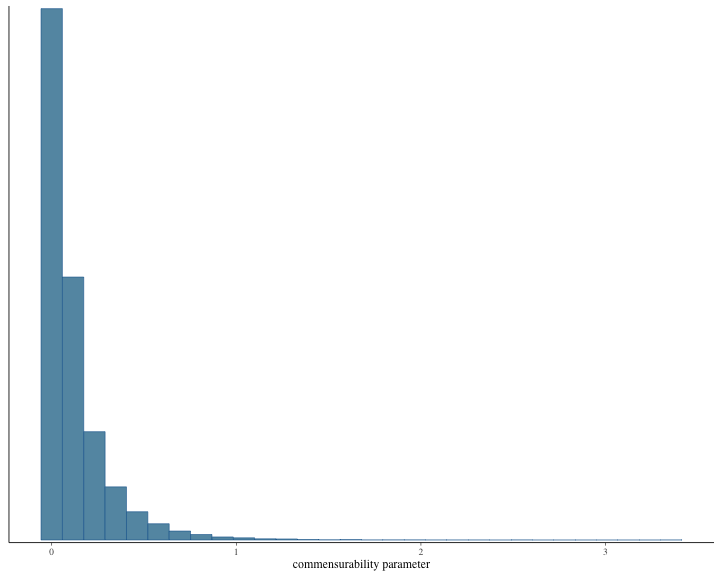
plot of chunk unnamed-chunk-10
bayesplot::color_scheme_set("mix-blue-pink")The credible interval can be calculated as follows.
summarize_draws(draws1, ~ quantile(.x, probs = c(0.025, 0.975)))
#> # A tibble: 6 × 3
#> variable `2.5%` `97.5%`
#> <chr> <dbl> <dbl>
#> 1 lp__ -722. -716.
#> 2 treatment log HR -0.571 -0.145
#> 3 baseline log hazard rate, internal -0.802 -0.447
#> 4 baseline log hazard rate, external 1.58 3.02
#> 5 commensurability parameter 0.000120 0.619
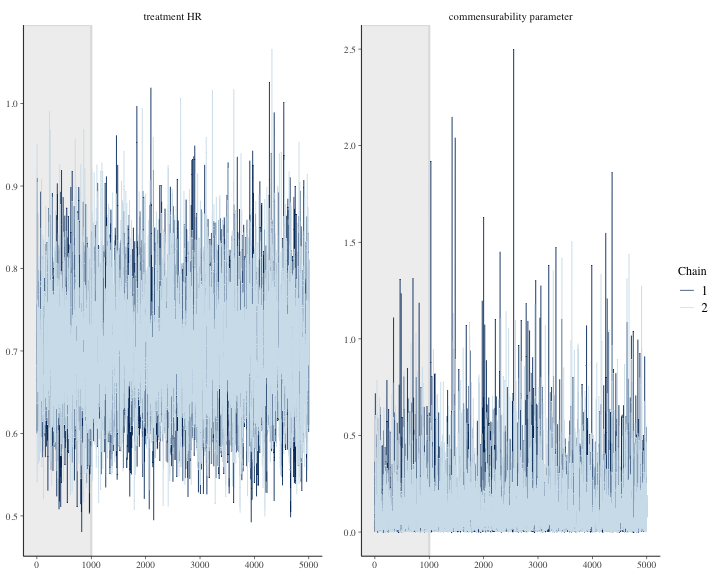
#> 6 treatment HR 0.565 0.865We can graph other plots that help us evaluate convergence and diagnose problems with the MCMC sampler, such as trace plot.
bayesplot::color_scheme_set("mix-blue-pink")
bayesplot::mcmc_trace(
draws1[1:(round(niter/2)), 1:2, ], # Using a subset of draws only
pars = c("treatment HR", "commensurability parameter"),
n_warmup = niter/10
)
plot of chunk unnamed-chunk-12
Time-to-event analysis with Weibull distribution and proportional hazards parametrization
We conduct analysis using a Weibull distribution for the outcome
model using the psborrow2 package as follows.
Non-informative normal prior is used for the baseline parameter . An exponential prior is used for the Weibull shape parameter .
#Outcome
outcome <- outcome_surv_weibull_ph(
time_var = "time",
cens_var = "cnsr",
shape_prior=prior_exponential(1),
baseline_prior = prior_normal(0, 1000),
weight_var = "norm.weights"
)
outcome
#> Outcome object with class OutcomeSurvWeibullPH
#>
#> Outcome variables:
#> time_var cens_var weight_var
#> "time" "cnsr" "norm.weights"
#>
#> Baseline prior:
#> Normal Distribution
#> Parameters:
#> Stan R Value
#> mu mean 0
#> sigma sd 1000
#>
#> shape_weibull prior:
#> Exponential Distribution
#> Parameters:
#> Stan R Value
#> beta rate 1
#> Constraints: <lower=0>Next, the borrowing method is implemented as shown below. We consider Bayesian Dynamic Borrowing (BDB) in which a non-informative gamma prior is assigned for the commensurability parameter.
#Borrowing
borrowing <- borrowing_hierarchical_commensurate(
ext_flag_col = "ext",
tau_prior = prior_gamma(0.001, 0.001)
)
borrowing
#> Borrowing object using the Bayesian dynamic borrowing with the hierarchical commensurate prior approach
#>
#> External control flag: ext
#>
#> Commensurability parameter prior:
#> Gamma Distribution
#> Parameters:
#> Stan R Value
#> alpha shape 0.001
#> beta rate 0.001
#> Constraints: <lower=0>Similarly, details regarding the treatment variable are specified below. Non-informative prior is used for treatment effect .
#Treatment
treatment <- treatment_details(
trt_flag_col = "group",
trt_prior = prior_normal(0, 1000)
)
treatment
#> Treatment object
#>
#> Treatment flag column: group
#>
#> Treatment effect prior:
#> Normal Distribution
#> Parameters:
#> Stan R Value
#> mu mean 0
#> sigma sd 1000Now, all the pieces are brought together to create the analysis object as shown below.
#Application
data_with_weights <- as.matrix(data_with_weights)
anls_obj <- create_analysis_obj(
data_matrix = data_with_weights,
outcome = outcome,
borrowing = borrowing,
treatment = treatment
)
#> Inputs look good.
#> Stan program compiled successfully!
#> Ready to go! Now call `mcmc_sample()`.Finally, we run the MCMC sample for iterations with chains.
results.weib.psborrow<- mcmc_sample(anls_obj,
iter_warmup = round(niter/3),
iter_sampling = niter,
chains = 3,
seed = 123
)
#> Running MCMC with 3 sequential chains...
#>
#> Chain 1 finished in 11.9 seconds.
#> Chain 2 finished in 12.8 seconds.
#> Chain 3 finished in 12.6 seconds.
#>
#> All 3 chains finished successfully.
#> Mean chain execution time: 12.4 seconds.
#> Total execution time: 37.5 seconds.
draws2 <- results.weib.psborrow$draws()
draws2 <- rename_draws_covariates(draws2, anls_obj)The summary is shown below.
results.weib.psborrow$summary()
#> # A tibble: 7 × 10
#> variable mean median sd mad q5 q95 rhat ess_bulk
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 lp__ -708. -7.07e+2 1.66 1.47 -7.11e+2 -705. 1.00 11655.
#> 2 beta_trt -0.300 -3.01e-1 0.110 0.110 -4.79e-1 -0.117 1.00 15789.
#> 3 alpha[1] -0.511 -5.09e-1 0.0936 0.0946 -6.67e-1 -0.361 1.00 15831.
#> 4 alpha[2] 1.97 1.99e+0 0.382 0.378 1.31e+0 2.55 1.00 21480.
#> 5 tau 0.182 7.54e-2 0.320 0.104 6.30e-4 0.710 1.00 14273.
#> 6 shape_weibull 0.836 8.36e-1 0.0319 0.0319 7.84e-1 0.889 1.00 21440.
#> 7 HR_trt 0.745 7.40e-1 0.0827 0.0817 6.20e-1 0.890 1.00 15789.
#> # ℹ 1 more variable: ess_tail <dbl>Histogram of the posterior samples for hazard ratio and commensurability parameter are produced.
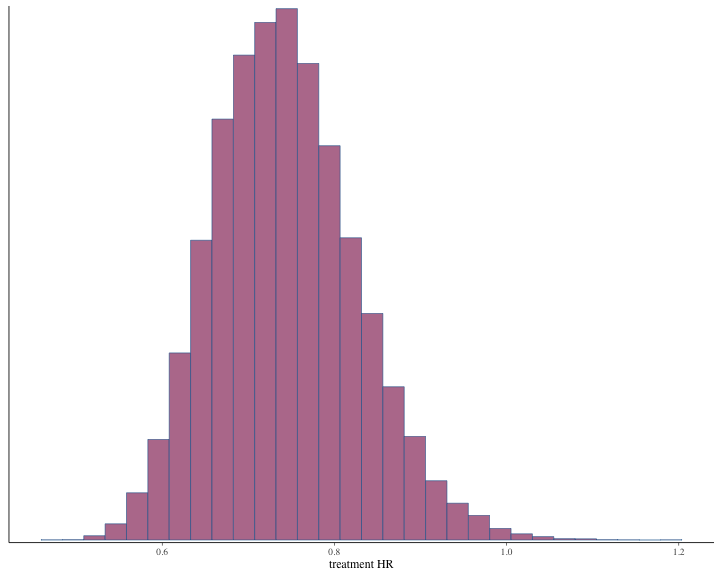
plot of chunk unnamed-chunk-19
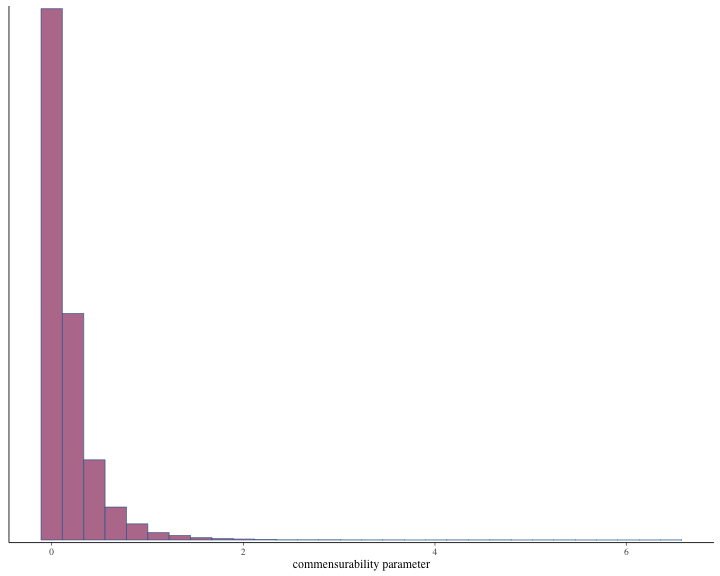
plot of chunk unnamed-chunk-19
bayesplot::color_scheme_set("mix-blue-pink")The credible interval can be calculated as follows.
summarize_draws(draws2, ~ quantile(.x, probs = c(0.025, 0.975)))
#> # A tibble: 7 × 3
#> variable `2.5%` `97.5%`
#> <chr> <dbl> <dbl>
#> 1 lp__ -712. -705.
#> 2 treatment log HR -0.513 -0.0816
#> 3 baseline log hazard rate, internal -0.699 -0.334
#> 4 baseline log hazard rate, external 1.16 2.64
#> 5 commensurability parameter 0.000165 0.957
#> 6 Weibull shape parameter 0.775 0.900
#> 7 treatment HR 0.599 0.922We can see other plots that help us evaluate convergence and diagnose problems with the MCMC sampler, such as trace plot.
bayesplot::color_scheme_set("mix-blue-pink")
bayesplot::mcmc_trace(
draws2[1:(round(niter/2)), 1:2, ], # Using a subset of draws only
pars = c("treatment HR", "commensurability parameter"),
n_warmup = round(niter/10)
)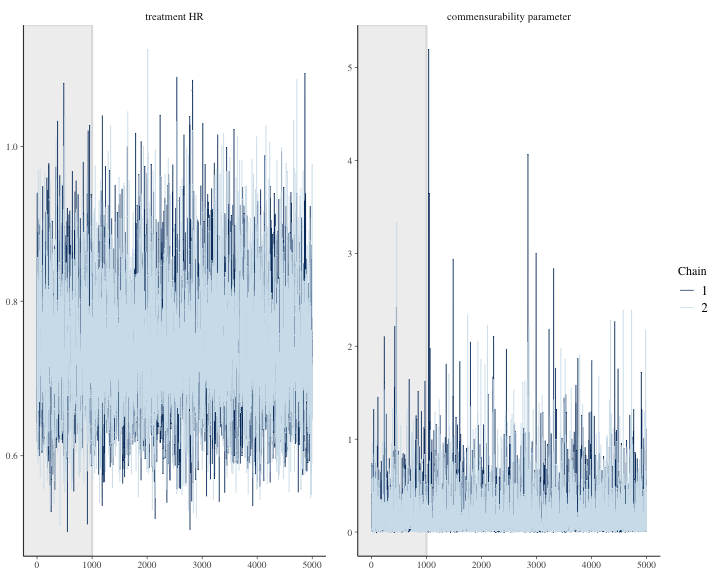
plot of chunk unnamed-chunk-21
Power prior with piecewise exponential distribution (not implemented
in psborrow2 R package)
We will consider the Bayesian power prior with subject specific power parameters. The weights from various matching and weighting methods can be used as subject specific power parameters for external control subjects. The baseline hazard function will be based on piecewise exponential distribution. The following JAGS code, adapted from (Alvares et al. 2021), implements the power prior with piecewise exponential baseline hazard. We will consider a subject specific power parameter as the weights from inverse probability weighting method. The subject specific weights for external control patients are normalized by dividing each weight by the maximum weight.
model{
#POWER PRIOR JAGS CODE
#Trial Data
for (i in 1:n){
# Pieces of the cumulative hazard function
for (k in 1:int.obs[i]) {
cond[i,k] <- step(time[i] - a[k + 1])
HH[i , k] <- cond[i,k] * (a[k + 1] - a[k]) * exp(alpha[k]) +
(1 - cond[i,k] ) * (time[i] - a[k]) * exp(alpha[k])
}
# Cumulative hazard function
H[i] <- sum(HH[i,1 : int.obs[i]] )
}
for ( i in 1:n) {
# Linear predictor
elinpred[i] <- exp(inprod(beta[],X[i,]))
# Log-hazard function
logHaz[i] <- log( exp(alpha[int.obs[i]]) * elinpred[i])
# Log-survival function
logSurv[i] <- -H[i] * elinpred[i]
# Definition of the log-likelihood using zeros trick
phi[i] <- 100000 - status[i] * logHaz[i] - logSurv[i]
zeros[i] ~ dpois(phi[i])
}
#Real World or External Control Data
for (i in 1:nR){
# Pieces of the cumulative hazard function
for (k in 1:int.obsR[i]) {
condR[i,k] <- step(timeR[i] - a[k + 1])
HHR[i , k] <- condR[i,k] * (a[k + 1] - a[k]) * exp(alpha[k]) +
(1 - condR[i,k] ) * (timeR[i] - a[k]) * exp(alpha[k])
}
# Cumulative hazard function
HR[i] <- sum(HHR[i,1 : int.obsR[i]] )
}
for ( i in 1:nR) {
# Linear predictor
elinpredR[i] <- exp(inprod(beta[],XR[i,]))
# Log-hazard function
logHazR[i] <- log(exp(alpha[int.obsR[i]]) * elinpredR[i])
# Log-survival function
logSurvR[i] <- -HR[i] * elinpredR[i]
# Definition of the log-likelihood using zeros trick
phiR[i] <- 100000 - rho[i] * statusR[i] * logHazR[i] - rho[i] * logSurvR[i]
#rho[i] is the subject level weight as a power prior
zerosR[i] ~ dpois(phiR[i])
}
# Prior distributions
for(l in 1: Nbetas ){
beta[l] ~ dnorm(0 , 0.001)
}
for( k in 1 :m) {
alpha[k] ~ dnorm(0,0.001)
}
} We now define all the variables as in input to JAGS.
data_with_weights=data.frame(data_with_weights)
#Trial Data
trial.data <- data_with_weights[data_with_weights$indicator==1,]
#External Control Data
ext.control.data <- data_with_weights[data_with_weights$indicator==0,]
#Input in JAGS code
n <- nrow(trial.data) #Sample size in trial data
nR <- nrow(ext.control.data) #Sample size in external control data
time <- trial.data$time #Survival time in trial data
timeR <- ext.control.data$time #Survival time in external control data
status <- trial.data$event #Event indicator in trial data
statusR <- ext.control.data$event #Event indicator in external control data
rho <- ext.control.data$invprob_weights/max(ext.control.data$invprob_weights) #Power prior weights
X <- as.matrix(trial.data[,10]) #Covariates in trial data
XR <- as.matrix(ext.control.data[,10]) #Covariates in external control data
Nbetas <- ncol(X)
zeros = rep(0, n)
zerosR = rep(0, nR)We also need to pre-specify the number of intervals. For simplicity, we will consider interval. However, this method also works .
# Time axis partition
K <- 1 # number of intervals
#Cut points (Using the event times in trial data)
a=c(0,quantile(trial.data$time[trial.data$event==1],seq(0,1,by=1/K))[-c(1,K+1)],
max(c(trial.data$time,ext.control.data$time))+0.0001)
#Trial data
# int.obs: vector that tells us at which interval each observation is
int.obs <- matrix(data = NA, nrow = nrow(trial.data), ncol = length(a) - 1)
d <- matrix(data = NA, nrow = nrow(trial.data), ncol = length(a) - 1)
for(i in 1:nrow(trial.data)) {
for(k in 1:(length(a) - 1)) {
d[i, k] <- ifelse(trial.data$time[i] - a[k] > 0, 1, 0) *
ifelse(a[k + 1] - trial.data$time[i] > 0, 1,0)
int.obs[i, k] <- d[i, k] * k
}
}
int.obs <- rowSums(int.obs)
#External control data
# int.obs: vector that tells us at which interval each observation is
int.obsR <- matrix(data = NA, nrow = nrow(ext.control.data), ncol = length(a) - 1)
d <- matrix(data = NA, nrow = nrow(ext.control.data), ncol = length(a) - 1)
for(i in 1:nrow(ext.control.data)) {
for(k in 1:(length(a) - 1)) {
d[i, k] <- ifelse(ext.control.data$time[i] - a[k] > 0, 1, 0) *
ifelse(a[k + 1] - ext.control.data$time[i] > 0, 1,0)
int.obsR[i, k] <- d[i, k] * k
}
}
int.obsR <- rowSums(int.obsR)We now put all variables into a list as data inputs for JAGs.
### JAGS ####
d.jags <- list("n", "nR", "time", "timeR",
"a", "X", "XR","int.obs",
"int.obsR","Nbetas",
"zeros","zerosR","rho",
"status", "statusR","K")We specify the parameter of interest as follows.
#Parameter of interest
p.jags <- c("beta","alpha")The standard normal distribution is used as an initial values for the parameter of interest.
#Initial values for each parameter
i.jags <- function(){
list(beta = rnorm(ncol(X)), alpha = rnorm(K))
}Now, we call the jags function to conduct MCMC sampling
with
chains as shown below. We set number of iterations as
with a burn in of
and thinning of
.
set.seed(1)
model1 <- jags(data = d.jags, model.file = "powerprior.txt", inits = i.jags, n.chains = 3,
parameters=p.jags,n.iter=niter,n.burnin = round(niter/2),n.thin = 10)
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 1100
#> Unobserved stochastic nodes: 2
#> Total graph size: 17432
#>
#> Initializing modelThe summary can be produced using the following command.
model1$BUGSoutput$summary
#> mean sd 2.5% 25% 50%
#> alpha -5.593230e-01 0.08814086 -7.325480e-01 -6.187778e-01 -5.577829e-01
#> beta -4.220429e-01 0.10645216 -6.269033e-01 -4.931953e-01 -4.208824e-01
#> deviance 2.200015e+08 1.98002031 2.200015e+08 2.200015e+08 2.200015e+08
#> 75% 97.5% Rhat n.eff
#> alpha -4.975311e-01 -3.800964e-01 1.003074 650
#> beta -3.470770e-01 -2.163331e-01 1.003200 630
#> deviance 2.200015e+08 2.200015e+08 1.000000 1The summary of the hazard ratio for treatment variable is shown below.
c(summary(exp(model1$BUGSoutput$sims.list$beta[,1])),
quantile(exp(model1$BUGSoutput$sims.list$beta[,1]),probs=c(0.025,0.975)))
#> Min. 1st Qu. Median Mean 3rd Qu. Max. 2.5% 97.5%
#> 0.4786944 0.6106720 0.6564673 0.6594231 0.7067509 0.9316665 0.5342440 0.8054669The histogram of the treatment hazard ratio can also be produced.
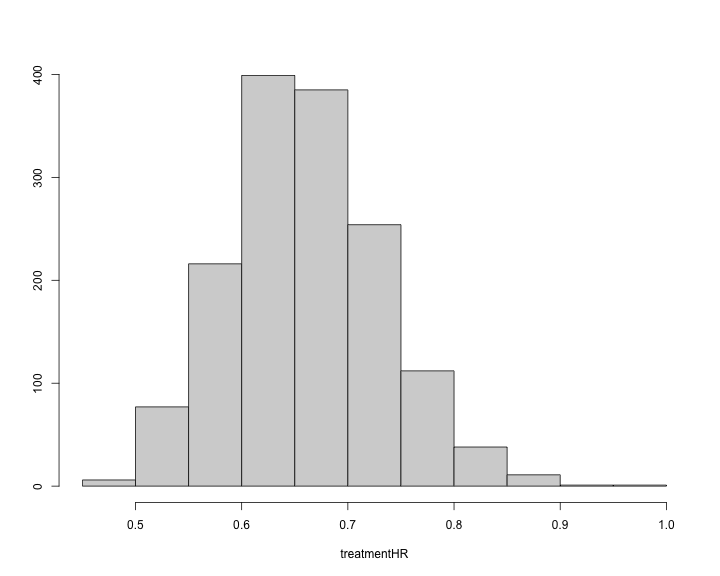
plot of chunk unnamed-chunk-31
The traceplot can be generated as follows.
traceplot(model1,varname=c("alpha","beta"))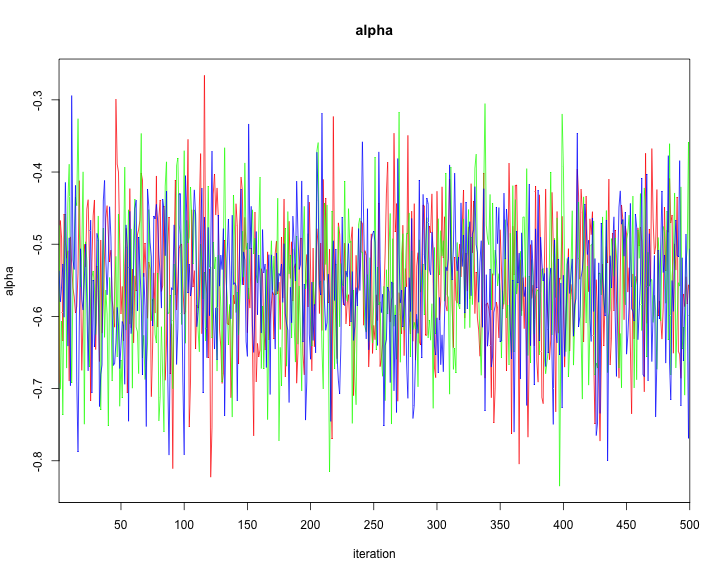
plot of chunk unnamed-chunk-32
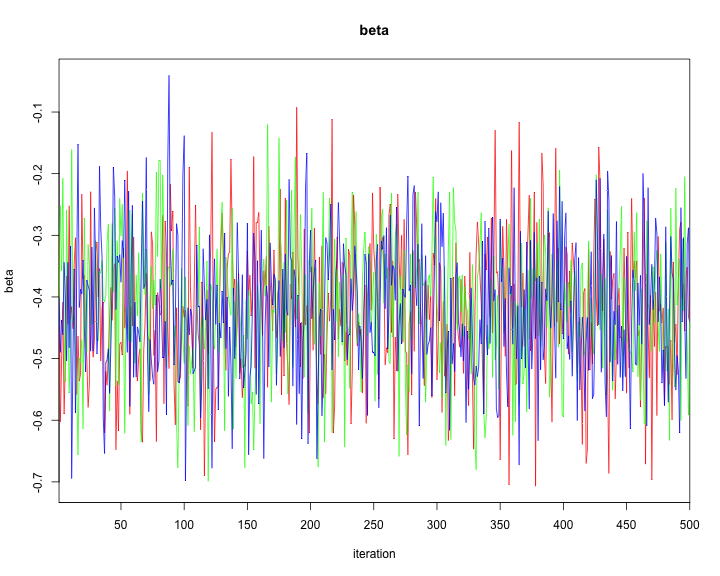
plot of chunk unnamed-chunk-32
Commensurate prior with piecewise exponential distribution (not
implemented in psborrow2 R package)
We will consider the Bayesian commensurate prior model.
model{
#Trial Data
for (i in 1:n){
# Pieces of the cumulative hazard function
for (k in 1:int.obs[i]) {
cond[i,k] <- step(time[i] - a[k + 1])
HH[i , k] <- cond[i,k] * (a[k + 1] - a[k]) * exp(alpha[k]) +
(1 - cond[i,k] ) * (time[i] - a[k]) * exp(alpha[k])
}
# Cumulative hazard function
H[i] <- sum(HH[i,1 : int.obs[i]] )
}
for ( i in 1:n) {
# Linear predictor
elinpred[i] <- exp(inprod(beta[],X[i,]))
# Log-hazard function
logHaz[i] <- log(exp(alpha[int.obs[i]]) * elinpred[i])
# Log-survival function
logSurv[i] <- -H[i] * elinpred[i]
# Definition of the log-likelihood using zeros trick
phi[i] <- 100000 - wt[i]*status[i] * logHaz[i] - wt[i]*logSurv[i]
zeros[i] ~ dpois(phi[i])
}
#Real World or External Control Data
for (i in 1:nR){
# Pieces of the cumulative hazard function
for (k in 1:int.obsR[i]) {
condE[i,k] <- step(timeR[i] - a[k + 1])
HHE[i , k] <- condE[i,k] * (a[k + 1] - a[k]) * exp(alphaR[k]) +
(1 - condE[i,k] ) * (timeR[i] - a[k]) * exp(alphaR[k])
}
# Cumulative hazard function
HE[i] <- sum(HHE[i,1 : int.obsR[i]] )
}
for ( i in 1:nR) {
# Linear predictor
elinpredE[i] <- exp(inprod(beta0[],XR[i,]))
# Log-hazard function
logHazE[i] <- log(exp(alphaR[int.obsR[i]]) * elinpredE[i])
# Log-survival function
logSurvE[i] <- -HE[i] * elinpredE[i]
# Definition of the log-likelihood using zeros trick
phiE[i] <- 100000 - wtR[i]*statusR[i] * logHazE[i] - wtR[i] * logSurvE[i]
zerosR[i] ~ dpois(phiE[i])
}
# Commensurate prior on the covariate effect
for(l in 1: Nbetas ){
beta0[l] ~ dnorm(0,0.0001);
tau[l] ~ dgamma(0.01,0.01);
beta[l] ~ dnorm(beta0[l],tau[l]);
}
# Normal prior on the piecewise exponential parameters for each interval
for( m in 1 : K) {
taualpha[m] ~ dgamma(0.01,0.01);
alpha[m] ~ dnorm(alphaR[m],taualpha[m]);
alphaR[m] ~ dnorm(0,0.0001);
}
} We now define all the variables as in input to JAGS.
data_with_weights=data.frame(data_with_weights)
#Trial Data
trial.data <- data_with_weights[data_with_weights$indicator==1,]
#External Control Data
ext.control.data <- data_with_weights[data_with_weights$indicator==0,]
#Input in JAGS code
n <- nrow(trial.data) #Sample size in trial data
nR <- nrow(ext.control.data) #Sample size in external control data
time <- trial.data$time #Survival time in trial data
timeR <- ext.control.data$time #Survival time in external control data
status <- trial.data$event #Event indicator in trial data
statusR <- ext.control.data$event #Event indicator in external control data
wt <- trial.data$norm.weights #Vector of weights in trial data
wtR <- ext.control.data$norm.weights #Vector of weights in external control data
X <- as.matrix(trial.data[,10]) #Treatment indicator in trial data
XR <- as.matrix(ext.control.data[,10]) #Treatment indicator in trial data
Nbetas <- ncol(X)
zeros = rep(0, n)
zerosR = rep(0, nR)We also need to pre-specify the number of intervals. For simplicity, we will consider interval. However, this method also works when .
# Time axis partition
K <- 1 # number of intervals
#Cut points (Using the event times in trial data)
a=c(0,quantile(trial.data$time[trial.data$event==1],seq(0,1,by=1/K))[-c(1,K+1)],
max(c(trial.data$time,ext.control.data$time))+0.0001)
#Trial data
# int.obs: vector that tells us at which interval each observation is
int.obs <- matrix(data = NA, nrow = nrow(trial.data), ncol = length(a) - 1)
d <- matrix(data = NA, nrow = nrow(trial.data), ncol = length(a) - 1)
for(i in 1:nrow(trial.data)) {
for(k in 1:(length(a) - 1)) {
d[i, k] <- ifelse(trial.data$time[i] - a[k] > 0, 1, 0) *
ifelse(a[k + 1] - trial.data$time[i] > 0, 1, 0)
int.obs[i, k] <- d[i, k] * k
}
}
int.obs <- rowSums(int.obs)
#External control data
# int.obs: vector that tells us at which interval each observation is
int.obsR <- matrix(data = NA, nrow = nrow(ext.control.data), ncol = length(a) - 1)
d <- matrix(data = NA, nrow = nrow(ext.control.data), ncol = length(a) - 1)
for(i in 1:nrow(ext.control.data)) {
for(k in 1:(length(a) - 1)) {
d[i, k] <- ifelse(ext.control.data$time[i] - a[k] > 0, 1, 0) *
ifelse(a[k + 1] - ext.control.data$time[i] > 0, 1,0)
int.obsR[i, k] <- d[i, k] * k
}
}
int.obsR <- rowSums(int.obsR)We now put all variables into a list as data inputs for JAGs. Note that the letter in the following corresponds to RWD. For example, is the covariate matrix in RWD.
### JAGS ####
d.jags <- list("n", "nR", "time", "timeR",
"a", "X", "XR","int.obs",
"int.obsR","Nbetas",
"zeros","zerosR","wt", "wtR",
"status", "statusR","K")We specify the parameter of interest as follows. Note that
alphaR is the baseline hazard parameter for external
control.
#Parameter of interest
p.jags <- c("beta","alpha","alphaR","tau")We generate initial values for and from standard normal distributions, and from a non-informative Gamma distribution.
#Initial values for each parameter
i.jags <- function(){
list(beta = rnorm(ncol(X)), beta0 = rnorm(ncol(X)),
alpha = rnorm(K),alphaR = rnorm(K),tau = rgamma(ncol(X),shape = 0.01,scale=0.01))
}Now, we call the jags function to conduct MCMC sampling
with
chains as shown below. We set number of iterations as
with a burn in of
and thinning of
.
set.seed(1)
model2 <- jags(data = d.jags, model.file = "commensurateprior.txt", inits = i.jags, n.chains = 3,
parameters=p.jags,n.iter=niter,n.burnin = round(niter/2),n.thin = 10)
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 1100
#> Unobserved stochastic nodes: 5
#> Total graph size: 18642
#>
#> Initializing modelThe summary can be produced using the following command.
model2$BUGSoutput$summary
#> mean sd 2.5% 25% 50%
#> alpha -6.207876e-01 0.08997989 -8.027429e-01 -6.804281e-01 -6.187626e-01
#> alphaR 2.332726e+00 0.38544878 1.517221e+00 2.080838e+00 2.353291e+00
#> beta -3.570740e-01 0.10944967 -5.737298e-01 -4.287050e-01 -3.588437e-01
#> deviance 2.200014e+08 2.57443363 2.200014e+08 2.200014e+08 2.200014e+08
#> tau 1.297205e-01 0.18216287 2.880458e-04 1.381331e-02 6.095153e-02
#> 75% 97.5% Rhat n.eff
#> alpha -5.638885e-01 -4.457021e-01 1.001797 1100
#> alphaR 2.615898e+00 3.014684e+00 1.004889 820
#> beta -2.823616e-01 -1.377196e-01 1.001395 1400
#> deviance 2.200014e+08 2.200014e+08 1.000000 1
#> tau 1.637742e-01 6.863053e-01 1.004178 1100The summary of the hazard ratio for treatment variable is shown below.
c(summary(exp(model2$BUGSoutput$sims.list$beta[,1])),
quantile(exp(model2$BUGSoutput$sims.list$beta[,1]),probs=c(0.025,0.975)))
#> Min. 1st Qu. Median Mean 3rd Qu. Max. 2.5% 97.5%
#> 0.4690294 0.6513520 0.6984835 0.7039318 0.7540010 1.0061228 0.5634205 0.8713433The histogram of the treatment hazard ratio can also be produced.
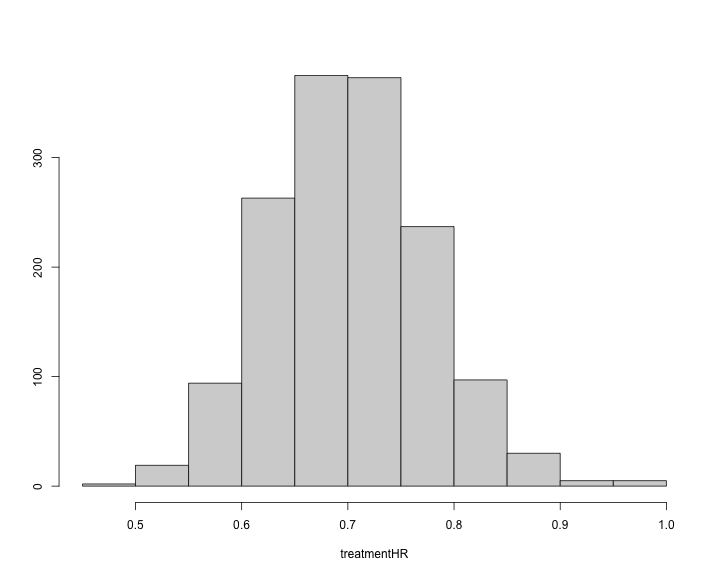
plot of chunk unnamed-chunk-42
The histogram of the commensurability parameter can also be produced.
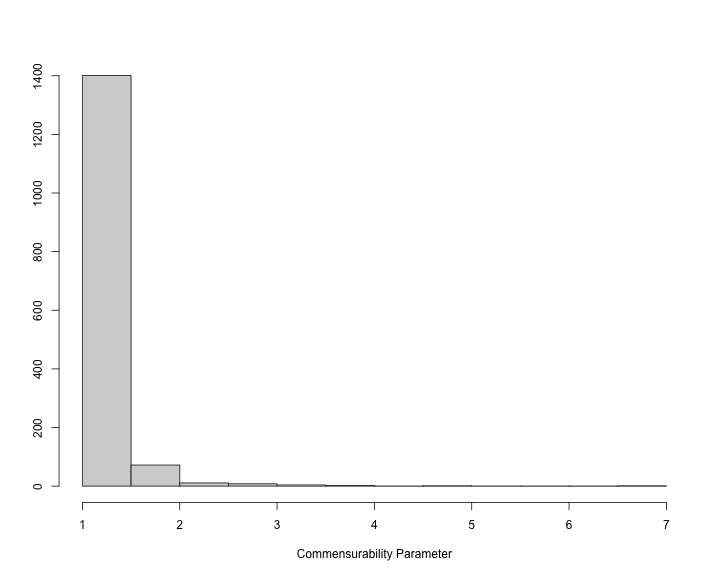
plot of chunk unnamed-chunk-43
The traceplot can be created as follows.
traceplot(model2,varname=c("alpha","alphaR","beta","tau"))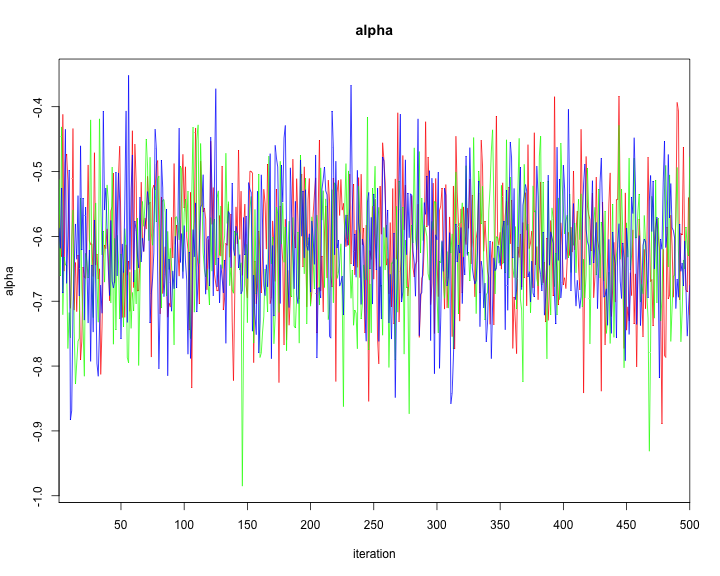
plot of chunk unnamed-chunk-44
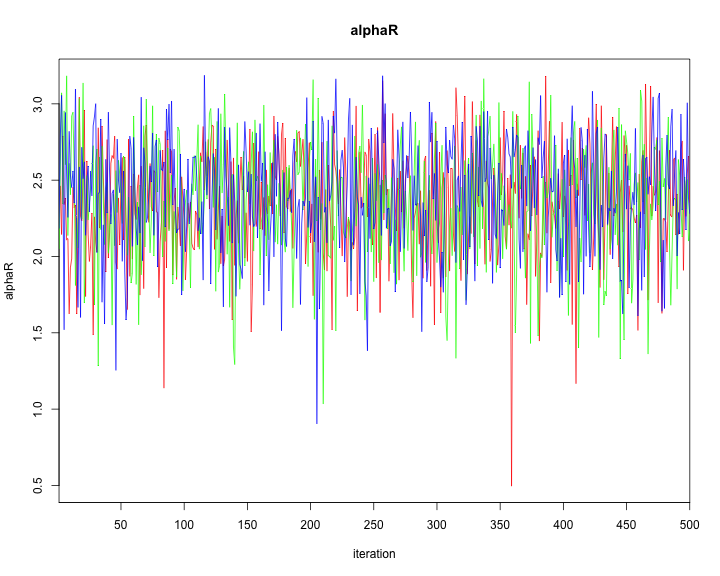
plot of chunk unnamed-chunk-44
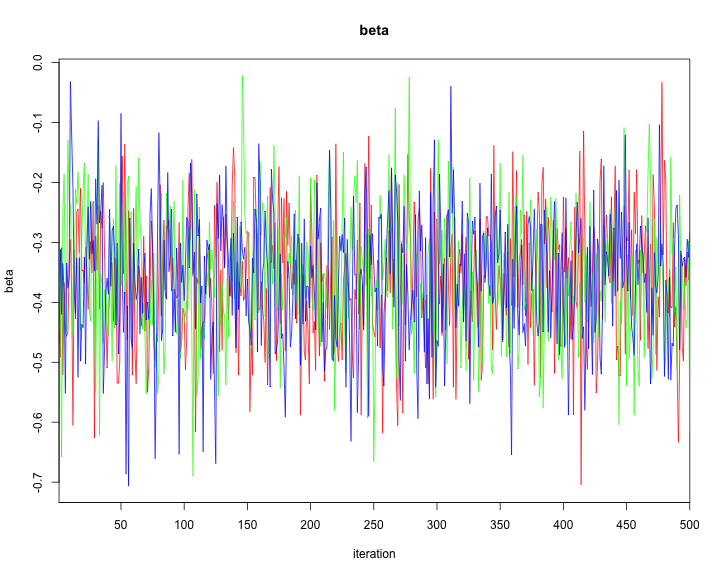
plot of chunk unnamed-chunk-44
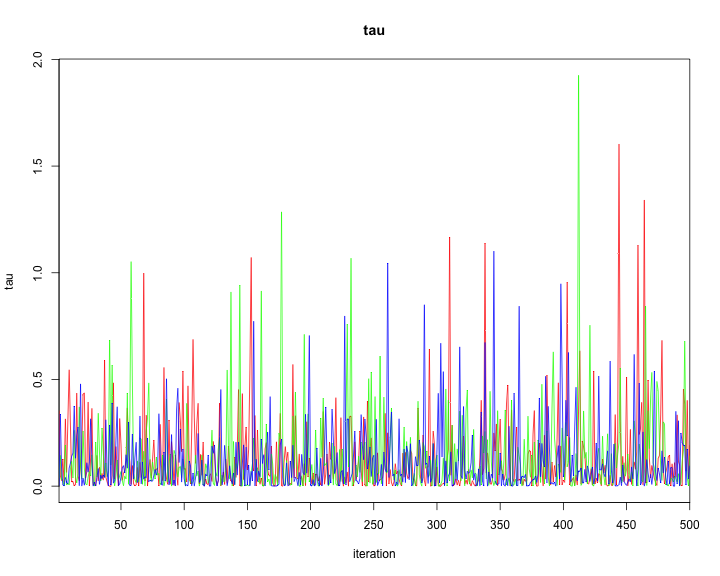
plot of chunk unnamed-chunk-44
Exponential distribution (constant hazard) and no borrowing: Using
psborrow2 R package
In addition to specifying an exponential distribution using Bayesian dynamic borrowing, naive no-borrowing and full-borrowing analysis can be conducted using the exponential distribution following similar steps as above. These type of analysis could be used as a sensitivity or exploratory analysis.
The psborrow2 package will be used to conduct the
analysis. Following are the steps.
We use exponential distribution for the outcome model as follows. Non-informative normal prior is used for the baseline parameter.
#Outcome
outcome <- outcome_surv_exponential(
time_var = "time",
cens_var = "cnsr",
baseline_prior = prior_normal(0, 1000)
)
outcome
#> Outcome object with class OutcomeSurvExponential
#>
#> Outcome variables:
#> time_var cens_var
#> "time" "cnsr"
#>
#> Baseline prior:
#> Normal Distribution
#> Parameters:
#> Stan R Value
#> mu mean 0
#> sigma sd 1000Next, the borrowing method is implemented as shown below. We consider no borrowing as shown below.
#Borrowing
borrowing <- borrowing_none(
ext_flag_col = "ext"
)
borrowing
#> Borrowing object using the No borrowing approach
#>
#> External control flag: extSimilarly, details regarding the treatment variable is specified below. Non-informative prior is used a prior for treatment effect.
#Treatment
treatment <- treatment_details(
trt_flag_col = "group",
trt_prior = prior_normal(0, 1000)
)
treatment
#> Treatment object
#>
#> Treatment flag column: group
#>
#> Treatment effect prior:
#> Normal Distribution
#> Parameters:
#> Stan R Value
#> mu mean 0
#> sigma sd 1000Now, all the pieces are brought together to create the analysis object as shown below.
data_with_weights <- as.matrix(data_with_weights)
#Application
anls_obj <- create_analysis_obj(
data_matrix = data_with_weights,
outcome = outcome,
borrowing = borrowing,
treatment = treatment
)
#> Inputs look good.
#> NOTE: excluding `ext` == `1`/`TRUE` for no borrowing.
#> Stan program compiled successfully!
#> Ready to go! Now call `mcmc_sample()`.Finally, we run the MCMC sample with chains.
results.no.psborrow<- mcmc_sample(anls_obj,
iter_warmup = round(niter/3),
iter_sampling = niter,
chains = 3,
seed = 123
)
#> Running MCMC with 3 sequential chains...
#>
#> Chain 1 finished in 1.7 seconds.
#> Chain 2 finished in 1.7 seconds.
#> Chain 3 finished in 1.8 seconds.
#>
#> All 3 chains finished successfully.
#> Mean chain execution time: 1.7 seconds.
#> Total execution time: 5.4 seconds.
draws3 <- results.no.psborrow$draws()
draws3 <- rename_draws_covariates(draws3, anls_obj)The summary is shown below.
results.no.psborrow$summary()
#> # A tibble: 4 × 10
#> variable mean median sd mad q5 q95 rhat ess_bulk
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 lp__ -727. -727. 1.03 0.719 -729. -726. 1.00 10367.
#> 2 beta_trt -0.357 -0.358 0.111 0.111 -0.537 -0.172 1.00 8928.
#> 3 alpha -0.622 -0.621 0.0926 0.0929 -0.775 -0.473 1.00 8752.
#> 4 HR_trt 0.704 0.699 0.0788 0.0775 0.585 0.842 1.00 8928.
#> # ℹ 1 more variable: ess_tail <dbl>The histogram of the posterior samples for hazard ratio and commensurability parameter as shown below.
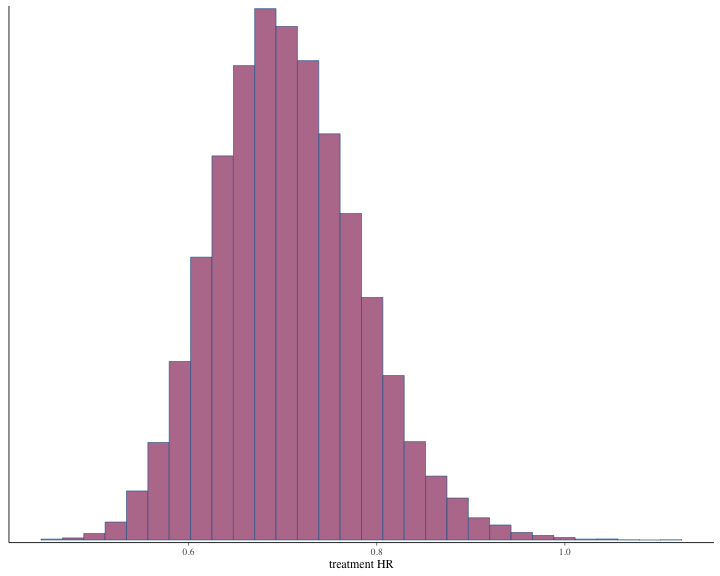
plot of chunk unnamed-chunk-51
bayesplot::color_scheme_set("mix-blue-pink")The credible interval can be calculated as follows.
summarize_draws(draws3, ~ quantile(.x, probs = c(0.025, 0.975)))
#> # A tibble: 4 × 3
#> variable `2.5%` `97.5%`
#> <chr> <dbl> <dbl>
#> 1 lp__ -730. -726.
#> 2 treatment log HR -0.571 -0.137
#> 3 baseline log hazard rate -0.807 -0.445
#> 4 treatment HR 0.565 0.872We can see other plots that help us understand and diagnose problems with the MCMC sampler, such as trace plot.
bayesplot::color_scheme_set("mix-blue-pink")
bayesplot::mcmc_trace(
draws3[1:(round(niter/2)), 1:2, ], # Using a subset of draws only
pars = c("treatment HR"),
n_warmup = round(niter/10)
)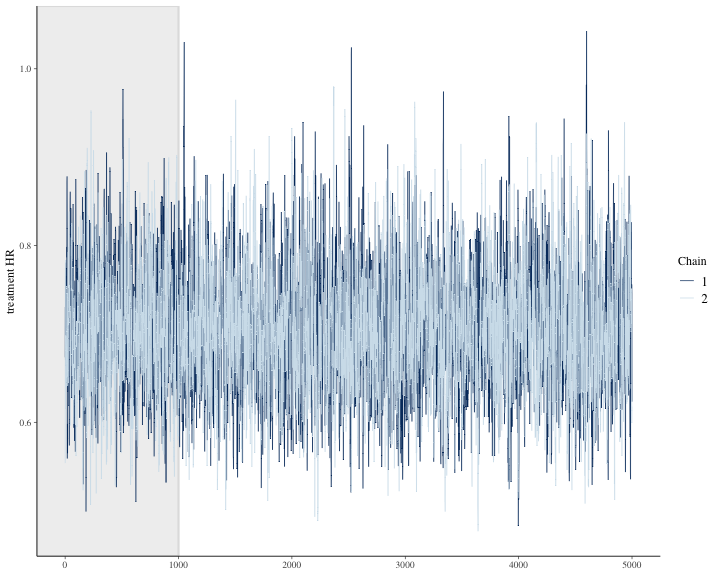
plot of chunk unnamed-chunk-53
Exponential distribution (constant hazard) and full borrowing: Using
psborrow2 R package
The psborrow2 package will be used to conduct the
analysis. Following are the steps.
We use exponential distribution for the outcome model as follows. Non-informative normal prior is used for the baseline parameter.
#Outcome
outcome <- outcome_surv_exponential(
time_var = "time",
cens_var = "cnsr",
baseline_prior = prior_normal(0, 1000)
)
outcome
#> Outcome object with class OutcomeSurvExponential
#>
#> Outcome variables:
#> time_var cens_var
#> "time" "cnsr"
#>
#> Baseline prior:
#> Normal Distribution
#> Parameters:
#> Stan R Value
#> mu mean 0
#> sigma sd 1000Next, the borrowing method is implemented as shown below. We consider full borrowing as shown below.
#Borrowing
borrowing <- borrowing_full(ext_flag_col = "ext")
borrowing
#> Borrowing object using the Full borrowing approach
#>
#> External control flag: extSimilarly, details regarding the treatment variable is specified below. Non-informative prior is used a prior for treatment effect.
#Treatment
treatment <- treatment_details(
trt_flag_col = "group",
trt_prior = prior_normal(0, 1000)
)
treatment
#> Treatment object
#>
#> Treatment flag column: group
#>
#> Treatment effect prior:
#> Normal Distribution
#> Parameters:
#> Stan R Value
#> mu mean 0
#> sigma sd 1000Now, all the pieces are brought together to create the analysis object as shown below.
#Application
anls_obj <- create_analysis_obj(
data_matrix = data_with_weights,
outcome = outcome,
borrowing = borrowing,
treatment = treatment
)
#> Inputs look good.
#> NOTE: dropping column `ext` for full borrowing.
#> Stan program compiled successfully!
#> Ready to go! Now call `mcmc_sample()`.Finally, we run the MCMC sample with chains.
results.full.psborrow<- mcmc_sample(anls_obj,
iter_warmup = round(niter/3),
iter_sampling = niter,
chains = 3,
seed = 123
)
#> Running MCMC with 3 sequential chains...
#>
#> Chain 1 finished in 3.0 seconds.
#> Chain 2 finished in 2.4 seconds.
#> Chain 3 finished in 2.5 seconds.
#>
#> All 3 chains finished successfully.
#> Mean chain execution time: 2.6 seconds.
#> Total execution time: 8.1 seconds.
draws4 <- results.full.psborrow$draws()
draws4 <- rename_draws_covariates(draws4, anls_obj)The summary is shown below.
results.full.psborrow$summary()
#> # A tibble: 4 × 10
#> variable mean median sd mad q5 q95 rhat ess_bulk
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 lp__ -747. -747. 1.00 0.709 -749. -746. 1.00 13222.
#> 2 beta_trt -1.51 -1.51 0.0763 0.0755 -1.64 -1.39 1.00 11880.
#> 3 alpha 0.535 0.535 0.0465 0.0465 0.458 0.610 1.00 11478.
#> 4 HR_trt 0.221 0.220 0.0169 0.0166 0.194 0.249 1.00 11880.
#> # ℹ 1 more variable: ess_tail <dbl>The histogram of the posterior samples for hazard ratio and commensurability parameter as shown below.
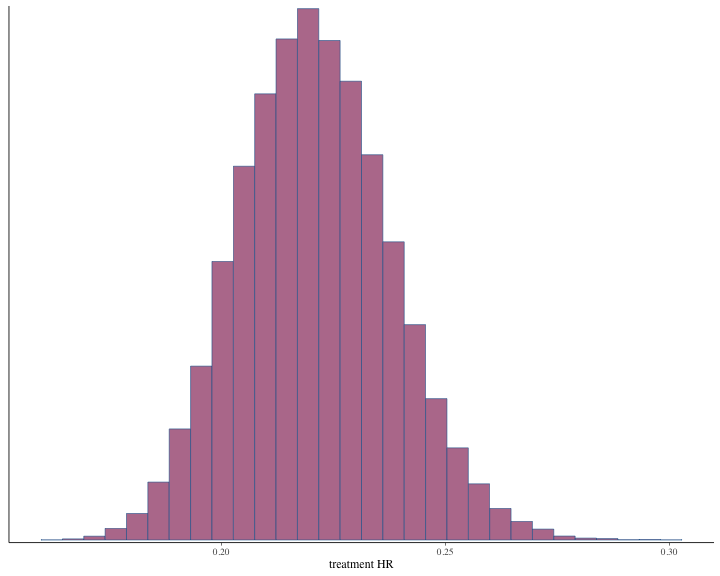
plot of chunk unnamed-chunk-60
bayesplot::color_scheme_set("mix-blue-pink")The credible interval can be calculated as follows.
summarize_draws(draws4, ~ quantile(.x, probs = c(0.025, 0.975)))
#> # A tibble: 4 × 3
#> variable `2.5%` `97.5%`
#> <chr> <dbl> <dbl>
#> 1 lp__ -750. -746.
#> 2 treatment log HR -1.66 -1.36
#> 3 baseline log hazard rate 0.442 0.623
#> 4 treatment HR 0.190 0.256We can see other plots that help us understand and diagnose problems with the MCMC sampler, such as trace plot.
bayesplot::color_scheme_set("mix-blue-pink")
bayesplot::mcmc_trace(
draws4[1:(round(niter/2)), 1:2, ], # Using a subset of draws only
pars = c("treatment HR"),
n_warmup = round(niter/10)
)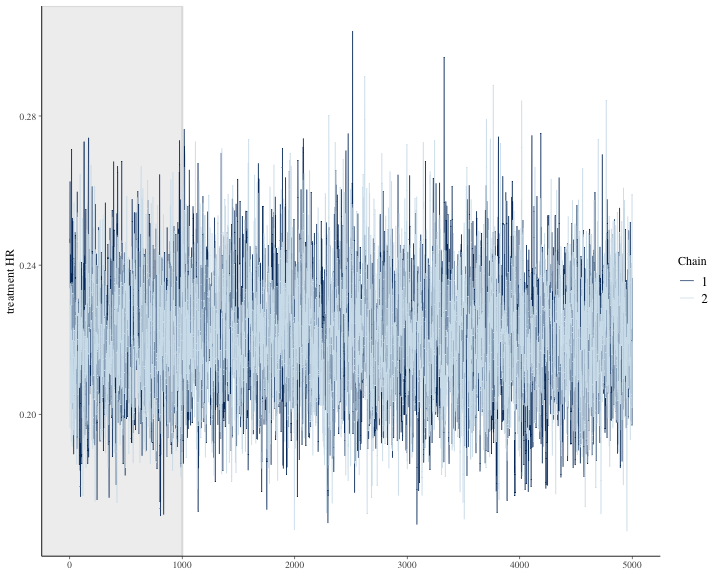
plot of chunk unnamed-chunk-62
Cox proportional hazards model using frequentist approach (No borrowing)
Now, we also demonstrate how researchers would fit a frequentist Cox model. For the first model, we will not borrow any information from external controls and use the trial data only.
data_with_weights = data.frame(data_with_weights)
f1 <- coxph(Surv(time,event)~group, data=data_with_weights[data_with_weights$ext==0,])
summary(f1)
#> Call:
#> coxph(formula = Surv(time, event) ~ group, data = data_with_weights[data_with_weights$ext ==
#> 0, ])
#>
#> n= 600, number of events= 389
#>
#> coef exp(coef) se(coef) z Pr(>|z|)
#> group -0.2540 0.7757 0.1105 -2.298 0.0216 *
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> exp(coef) exp(-coef) lower .95 upper .95
#> group 0.7757 1.289 0.6246 0.9633
#>
#> Concordance= 0.527 (se = 0.013 )
#> Likelihood ratio test= 5.1 on 1 df, p=0.02
#> Wald test = 5.28 on 1 df, p=0.02
#> Score (logrank) test = 5.31 on 1 df, p=0.02Cox proportional hazards model using frequentist approach (Full borrowing from external control)
A frequentist Cox model can also be fitted using all of the external control data via full borrowing.
f2 <- coxph(Surv(time,event)~group, data=data_with_weights)
summary(f2)
#> Call:
#> coxph(formula = Surv(time, event) ~ group, data = data_with_weights)
#>
#> n= 1100, number of events= 727
#>
#> coef exp(coef) se(coef) z Pr(>|z|)
#> group -1.10052 0.33270 0.07978 -13.79 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> exp(coef) exp(-coef) lower .95 upper .95
#> group 0.3327 3.006 0.2845 0.389
#>
#> Concordance= 0.664 (se = 0.007 )
#> Likelihood ratio test= 198.5 on 1 df, p=<2e-16
#> Wald test = 190.3 on 1 df, p=<2e-16
#> Score (logrank) test = 205.9 on 1 df, p=<2e-16Summarizing all the results together
Now, we concatenate the results from all of the Bayesian and frequentist analysis approaches together.
hr1=results.exp.psborrow$summary()[6,c(2)]
hr1conf = summarize_draws(draws1, ~ quantile(.x, probs = c(0.025, 0.975)))[6,c(2,3)]
hr1.conf=c(hr1$mean,hr1conf$`2.5%`,hr1conf$`97.5%`)
hr2=c(mean(exp(model1$BUGSoutput$sims.list$beta[,1])),
quantile(exp(model1$BUGSoutput$sims.list$beta[,1]),probs=c(0.025,0.975)))
hr2.conf=c(hr2)
hr3=results.weib.psborrow$summary()[7,c(2)]
hr3conf = summarize_draws(draws2, ~ quantile(.x, probs = c(0.025, 0.975)))[7,c(2,3)]
hr3.conf=c(hr3$mean,hr3conf$`2.5%`,hr3conf$`97.5%`)
hr4=c(mean(exp(model2$BUGSoutput$sims.list$beta[,1])),
quantile(exp(model2$BUGSoutput$sims.list$beta[,1]),probs=c(0.025,0.975)))
hr4.conf=c(hr4)
hr5=results.no.psborrow$summary()[4,c(2)]
hr5conf = summarize_draws(draws3, ~ quantile(.x, probs = c(0.025, 0.975)))[4,c(2,3)]
hr5.conf=c(hr5$mean,hr5conf$`2.5%`,hr5conf$`97.5%`)
hr6=results.full.psborrow$summary()[4,c(2)]
hr6conf = summarize_draws(draws4, ~ quantile(.x, probs = c(0.025, 0.975)))[4,c(2,3)]
hr6.conf=c(hr6$mean,hr6conf$`2.5%`,hr6conf$`97.5%`)
hr7.conf=c(exp(coef(f1)),exp(confint(f1)))
hr8.conf=c(exp(coef(f2)),exp(confint(f2)))
out = round(rbind(hr1.conf,hr2.conf,hr3.conf,hr4.conf,hr5.conf,hr6.conf,hr7.conf,hr8.conf),4)
rownames(out)= NULL
out = data.frame(Method=c("Exponential distribution (constant hazard) and gamma prior",
"Piecewise exponential distribution (proportional hazard) and power prior",
"Weibull distribution (proportional hazard) and gamma prior",
"Piecewise exponential distribution (proportional hazard) and commensurate prior",
"Exponential distribution (constant hazard): No borrowing",
"Exponential distribution (constant hazard): Full borrowing",
"Cox model (Frequentist approach): No borrowing",
"Cox model (Frequentist approach): Full borrowing"),out)
colnames(out)[2:4] = c("Hazard Ratio","Lower 95% CI","Upper 95% CI")The hazard ratio estimates and credible intervals for all the methods are shown below.
| Method | Hazard Ratio | Lower 95% CI | Upper 95% CI |
|---|---|---|---|
| Exponential distribution (constant hazard) and gamma prior | 0.7035 | 0.5652 | 0.8648 |
| Piecewise exponential distribution (proportional hazard) and power prior | 0.6594 | 0.5342 | 0.8055 |
| Weibull distribution (proportional hazard) and gamma prior | 0.7453 | 0.5987 | 0.9216 |
| Piecewise exponential distribution (proportional hazard) and commensurate prior | 0.7039 | 0.5634 | 0.8713 |
| Exponential distribution (constant hazard): No borrowing | 0.7043 | 0.5651 | 0.8718 |
| Exponential distribution (constant hazard): Full borrowing | 0.2210 | 0.1898 | 0.2558 |
| Cox model (Frequentist approach): No borrowing | 0.7757 | 0.6246 | 0.9633 |
| Cox model (Frequentist approach): Full borrowing | 0.3327 | 0.2845 | 0.3890 |
Note: CI: Credible Interval for Bayesian methods and Confidence interval for Frequentist method